 HTTP网络请求
HTTP网络请求
# 简述 HTTPS 加密过程

HTTPS 使用 TLS/SSL 协议进行加密,主要包含以下步骤:
# 1.客户端发起请求
- 发送支持的加密算法列表
- 发送随机数 Client Random
# 2.服务器回应
- 选择加密算法
- 发送数字证书(包含公钥)
- 发送随机数 Server Random
# 3.客户端验证证书
- 验证证书是否由可信 CA 签发
- 验证证书域名是否匹配
- 验证证书是否在有效期内
# 4.生成会话密钥
- 客户端生成随机数 Pre-master secret
- 使用服务器公钥加密 Pre-master secret
- 客户端和服务器都通过三个随机数生成会话密钥 (Client Random + Server Random + Pre-master secret)
# 5.开始加密通信
- 双方使用会话密钥进行对称加密通信
- 保证通信内容的机密性和完整性
特点:
- 采用混合加密:非对称加密传输密钥,对称加密传输数据
- 数字证书保证服务器身份可信
- 具有防篡改和不可否认性
扩展:图解SSL/TLS协议 (opens new window)
# TCP 是如何建立连接的,三次握手,四次挥手
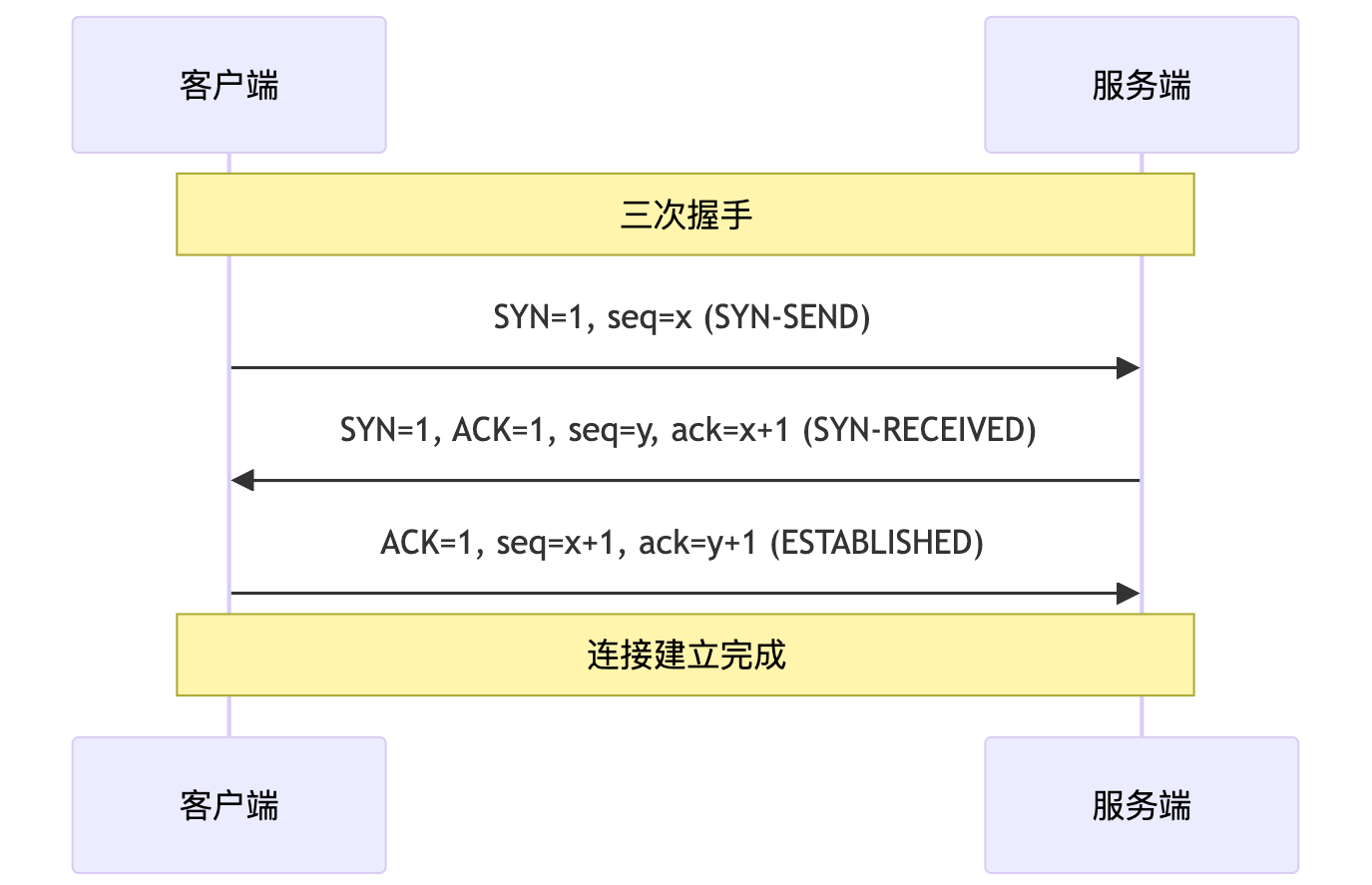
三次握手
- 客户端向服务端发送建立连接请求,客户端进入 SYN-SEND 状态
- 服务端收到建立连接请求后,向客户端发送一个应答,服务端进入 SYN-RECEIVED 状态
- 客户端接收到应答后,向服务端发送确认接收到应答,客户端进入 ESTABLISHED 状态
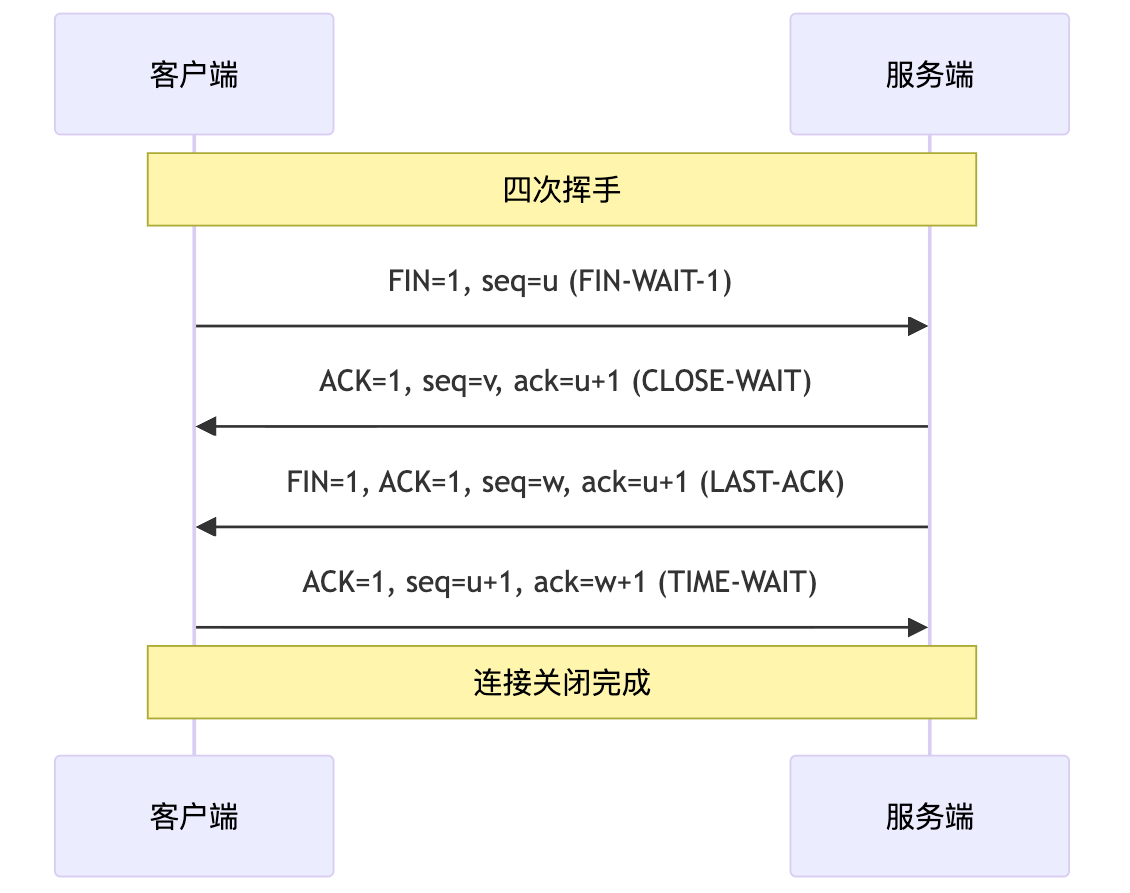
四次挥手
- 客户端向服务端发送断开连接请求
- 服务端收到断开连接请求后,告诉应用层去释放 tcp 连接
- 服务端向客户端发送最后一个数据包 FINBIT ,服务端进入 LAST-ACK 状态
- 客户端收到服务端的断开连接请求后,向服务端确认应答
三次握手四次挥手,客户端都是主动方,服务端都是被动方。在状态方面:三次握手的客户端和服务端都是由原来的 closed 变为 established,四次挥手的客户端和服务端都是由原来的 established 变为 closed。
# HTTP 几个版本的区别
# HTTP/0.9
- 仅支持 GET 请求,无请求头和请求体
- 只能传输 HTML 文件,返回 ASCII 字符流
- 无响应头
缺点:功能极其有限
# HTTP/1.0 多类型支持
- 支持多种文件类型(不限于 ASCII)
- 引入请求头和响应头(key-value 形式)
- 每个请求都需要建立新的 TCP 连接
缺点:频繁连接导致性能开销
# HTTP/1.1 持久连接
- 引入持久连接(keep-alive): 一个 TCP 连接可传输多个 HTTP 请求
- 默认开启 keep-alive,通常限制 6-8 个并发连接
- 引入 Host 字段,支持虚拟主机
- 引入 Chunk transfer 机制处理动态内容长度
缺点:存在队头阻塞问题(前面的请求阻塞后续请求)
# HTTP/2.0 多路复用
- 一个域名仅使用一个 TCP 长连接
- 引入二进制分帧层,实现多路复用(并行传输请求)
- 支持请求优先级
- 强制使用 HTTPS(HTTP + TLS 加密)
仍依赖 TCP,存在 TCP 队头阻塞问题
# HTTP/3.0 QUIC 协议
- 基于 UDP 协议而非 TCP
- 实现了类似 TCP 的流量控制和可靠传输
- 继承 TLS 加密
- 多路费用
- 解决 TCP 对头阻塞问题
# HTTP 常见的状态码
# 1. 2xx 成功状态码
# 重点解析
- 200 OK:最基础的成功状态码,表示请求完全成功。
- 204 No Content:成功但无返回数据,适用于不需要返回内容的操作(如
DELETE)。 - 205 Reset Content:要求客户端重置当前视图(如提交表单后清空输入框)。
- 206 Partial Content:支持分块传输(如视频流、大文件下载)。
# 实际场景
- 204:删除资源后,服务器只需确认成功,无需返回数据。
- 206:浏览器下载大文件时,通过
Range头实现断点续传,服务器返回206和部分内容。
# 2. 3xx 重定向状态码
# 重点解析
- 301 vs 302:
- 301:永久重定向,搜索引擎会更新链接到新地址。
- 302:临时重定向,搜索引擎仍保留原地址。
- 303:强制客户端用
GET方法访问新地址(避免POST重复提交)。 - 304:协商缓存,通过
ETag或Last-Modified判断资源是否修改。
# 实际场景
- 301:网站域名更换,旧域名永久跳转到新域名。
- 302:用户未登录时临时跳转到登录页。
- 304:浏览器缓存未过期,直接使用本地资源,减少服务器压力。
# 3. 4xx 客户端错误状态码
# 重点解析
- 400:请求语法错误(如 JSON 格式错误)。
- 401 vs 403:
- 401:未认证(如未登录或
token失效)。 - 403:已认证但无权限(如普通用户访问管理员接口)。
- 401:未认证(如未登录或
- 404:资源不存在(可能是 URL 拼写错误)。
# 实际场景
- 401:前端未携带
token访问需要认证的接口。 - 403:用户尝试删除他人数据时被拒绝。
- 404:输入错误的 API 路径。
# 4. 5xx 服务端错误状态码
# 重点解析
- 500:服务器内部错误(如代码抛出未捕获的异常)。
- 501:服务器不支持请求的功能(如调用了未实现的 API)。
- 503:服务不可用(如服务器过载或维护)。
# 实际场景
- 500:数据库连接失败导致服务崩溃。
- 503:电商大促时服务器流量激增,暂时限流。
# 面试加分点
缓存机制:
- 提到
304时,可以展开说:- 浏览器通过
If-Modified-Since(基于时间)或If-None-Match(基于ETag)发起条件请求。 - 服务器比对后决定返回
304或200。
- 浏览器通过
- 提到
安全设计:
- 403 可以结合敏感词过滤或权限系统设计。
- 401 需提到
JWT或OAuth认证流程。
性能优化:
- 206 用于优化大文件传输。
- 301 减少重复跳转的开销。
高可用:
- 如何避免
503?- 答案:负载均衡、服务降级、限流策略(如令牌桶)。
- 如何避免
# 模拟面试问题
问题:用户登录后访问某个接口返回
403,可能是什么原因?
回答:可能是权限不足(如普通用户访问管理员接口),或请求被风控系统拦截(如敏感操作)。问题:如何实现文件的断点续传?
回答:客户端通过Range头指定下载范围,服务器返回206和部分内容,并支持ETag校验文件一致性。问题:
304是如何减少带宽消耗的?
回答:浏览器缓存资源后,下次请求携带If-None-Match(ETag),若资源未修改,服务器返回304,浏览器直接使用缓存。
# HTTP 常见 Header
# 请求头
- accept: text/html 告诉服务端我期望接收到一个html的文件
- accept-encoding: gzip, deflate, br 告诉服务端以这种方式压缩
- accept-language: zh-CN 告诉服务端以中文的格式返回
- authorization: 告诉服务端授权信息
- cookie: 告诉服务端客户端存储的 cookie
- origin: 告诉服务端请求的来源
# 响应头
- content-encoding: br 告诉浏览器压缩方式是br
- content-type: text/html; charset=utf-8 告诉浏览器以这种方式,编码加载
- cache-control: 告诉浏览器缓存策略
- expires: 告诉浏览器缓存过期时间
- set-cookie: 告诉浏览器设置 cookie
- access-control-allow-origin: * 告诉浏览器允许跨域
# URL 包含哪些部分
- 协议
- 域名
- 端口号
- 路径
- 查询参数
- 锚点
# Ajax Fetch Axios 三者有什么区别
Ajax、Fetch 和 Axios 都是用于发送 HTTP 请求的技术,但有以下区别:
# Ajax (Asynchronous JavaScript and XML)
- 是一种技术统称,不是具体的 API
- 最常用的实现是 XMLHttpRequest (XHR)
- 写法比较繁琐,需要手动处理各种状态
- 回调地狱问题
- 不支持 Promise
# Fetch
- 浏览器原生 API
- 基于 Promise
- 更简洁的写法
- 不需要额外引入
- 只对网络请求报错,对 400、500 都当做成功的请求
- 默认不带 cookie
- 不支持请求超时控制
- 不支持请求取消
- 不支持请求进度监控
# Axios
- 第三方库,需要额外引入
- 基于 Promise
- 支持浏览器和 Node.js
- 请求/响应拦截器
- 自动转换 JSON 数据
- 客户端支持防止 XSRF
- 支持请求取消
- 支持请求超时控制
- 支持请求进度监控
- 支持并发请求
- 自动转换请求和响应数据
# Fetch 和 XMLHTTPRequest 有什么区别
Fetch 和 XMLHTTPRequest 都是浏览器提供的 API,用于发送 HTTP 请求,但有以下区别:
# 语法和使用
- Fetch 基于 Promise,代码更简洁优雅
- XHR 使用回调函数,容易产生回调地狱
- Fetch 的 API 设计更简单现代
- XHR 的 API 设计较老,使用相对复杂
# 功能特性
- Fetch 默认不发送 cookies,需要配置 credentials
- XHR 默认发送 cookies
- Fetch 不能监听上传进度
- XHR 可以监听上传和下载进度
- Fetch 不能直接取消请求(需要 AbortController)
- XHR 可以通过 abort() 直接取消请求
# 错误处理
- Fetch 只有网络错误才会 reject,HTTP 错误码不会导致 reject
- XHR 可以处理所有类型的错误,包括 HTTP 错误码
# 浏览器支持
- Fetch 是现代浏览器标准 API
- XHR 有更好的浏览器兼容性,包括旧版本
# 什么是 Restful API
RESTful API 是一种软件架构风格,用于设计网络应用程序的接口。主要特点:
# 资源导向
- 使用 URL 定位资源
- 每个资源都有唯一的 URL
- 资源可以有多种表现形式(如 JSON、XML)
# HTTP 方法对应操作
- GET:获取资源
- POST:创建资源
- PUT:更新资源(完整更新)
- PATCH:更新资源(部分更新)
- DELETE:删除资源
# 无状态
- 服务器不保存客户端状态
- 每个请求包含所需的所有信息
- 有利于横向扩展
# 统一接口
- 使用标准的 HTTP 方法
- 使用标准的 HTTP 状态码
- 返回格式一致(通常是 JSON)
# 什么是 GraphQL
GraphQL 是一种用于 API 的查询语言和运行时,由 Facebook 开发。主要特点:
# 查询灵活性
- 客户端可以精确指定需要哪些数据
- 可以在一个请求中获取多个资源
- 避免了传统 REST API 的过度获取和获取不足问题
# 类型系统
- 强类型的 Schema 定义
- 自动生成文档
- 开发时有更好的类型提示
# 单个端点
- 只需要一个 API 端点
- 所有查询都发送到同一个地址
- 通过查询语句区分不同的操作
# 主要操作类型
- Query:获取数据
- Mutation:修改数据
- Subscription:实时数据订阅
# 优点
- 减少网络请求
- 避免版本化问题
- 强类型保障
- 更好的开发体验
# 缺点
- 学习成本较高
- 缓存较为复杂
- 服务端实现复杂度增加
# 如何理解 cookie
Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据。
# 主要特点
- 由服务器生成,浏览器进行存储
- 每次请求时会自动携带对应域名下的 cookie
- 可设置过期时间
- 默认情况下随着浏览器关闭而删除(会话 cookie)
# 常用属性
- name:cookie 名称
- value:cookie 值
- domain:指定 cookie 所属域名
- path:指定 cookie 所属路径
- expires/max-age:过期时间
- secure:只在 HTTPS 下传输
- httpOnly:禁止 JS 访问
- sameSite:跨站点请求限制
# 使用场景
- 会话状态管理(用户登录状态、购物车等)
- 个性化设置(用户偏好、主题等)
- 浏览器行为跟踪(分析用户行为等)
# 限制
- 大小限制:通常为 4KB
- 数量限制:每个域名下的 cookie 数量有限
- 安全性:明文传输(除非使用 HTTPS)
- 作用域:只能在所属域名下使用
# 为何现代浏览器都禁用第三方 cookie
主要原因是保护用户隐私和安全:
# 隐私问题
- 第三方 Cookie 可以跨站点追踪用户行为
- 广告商可以构建用户画像和浏览历史
- 用户数据可能被未经授权收集和使用
# 安全风险
- 增加 CSRF(跨站请求伪造)攻击风险
- 可能被用于会话劫持
- 恶意网站可能滥用第三方 Cookie
# 技术影响
- Safari 和 Firefox 已默认禁用第三方 Cookie
- Chrome 计划在 2024 年完全禁用第三方 Cookie
- 替代方案:
- First-Party Cookie
- localStorage
- Privacy Sandbox
- FLoC (Federated Learning of Cohorts)
# 如何理解 Session
Session 是服务器端的会话管理机制:
# 基本概念
- 服务器为每个用户创建的临时会话存储空间
- 用于保存用户的会话状态
- 通过 SessionID 来识别不同用户
- SessionID 通常保存在 Cookie 中
# 工作流程
- 用户首次访问服务器时,服务器创建 Session 并生成 SessionID
- 服务器将 SessionID 通过 Cookie 发送给客户端
- 客户端后续请求会自动携带包含 SessionID 的 Cookie
- 服务器通过 SessionID 找到对应 Session 并识别用户
# 特点
- 安全性较高:敏感数据存储在服务器
- 服务器负载较大:需要存储所有用户的 Session
- 依赖 Cookie:通常需要 Cookie 来存储 SessionID
- 集群问题:需要考虑 Session 共享
# 使用场景
- 用户登录状态管理
- 购物车
- 权限验证
- 表单验证
# 与 Cookie 的区别
- 存储位置:Session 在服务器,Cookie 在客户端
- 安全性:Session 较安全,Cookie 相对不安全
- 存储容量:Session 容量较大,Cookie 通常限制 4KB
- 性能:Session 消耗服务器资源,Cookie 消耗带宽资源
# 什么是 JWT 描述它的工作过程
JWT (JSON Web Token) 是一种开放标准,用于在各方之间安全地传输信息。
# 组成部分(用 . 分隔的三部分)
- Header(头部):指定加密算法和令牌类型
- Payload(负载):包含声明(claims)的实际数据
- Signature(签名):对前两部分的签名,用于验证消息未被篡改
# 工作流程
# 1.用户登录成功后,服务器创建 JWT
- 设置 Header 和 Payload
- 使用密钥生成签名
- 将三部分组合成 token
# 2.服务器将 token 返回给客户端
- 客户端存储在 localStorage 或 cookie 中
# 3.客户端后续请求携带 token
- 通常放在 Authorization header
- 格式:Bearer
<token>
# 4.服务器验证 token
- 检查签名是否有效
- 验证是否过期
- 验证其他声明(claims)
# 特点
- 无状态:服务器不需要存储会话信息
- 可扩展:负载部分可以包含自定义数据
- 跨域友好:可以在不同域名下使用
- 性能好:验证在服务端完成,不需要查询数据库
# 安全考虑
- 不要在 payload 中存储敏感信息
- 设置合理的过期时间
- 使用 HTTPS 传输
- 妥善保管签名密钥
# JWT 如何自动更新 token
JWT token 自动更新主要有以下几种方案:
# 双 token 机制
- access token:短期令牌,用于接口认证
- refresh token:长期令牌,用于刷新 access token
- 优点:安全性高,即使 access token 泄露影响有限
- 缺点:实现相对复杂,需要额外存储 refresh token
# 工作流程
- 用户登录后获取 access token 和 refresh token
- 使用 access token 访问接口
- access token 过期时,使用 refresh token 获取新的 access token
- refresh token 过期时,需要重新登录
// 前端示例代码
async function request(url, options) {
try {
const res = await fetch(url, {
...options,
headers: {
Authorization: `Bearer ${getAccessToken()}`,
},
})
if (res.status === 401) {
// access token 过期,尝试刷新
const newToken = await refreshToken()
if (newToken) {
// 使用新 token 重试请求
return request(url, options)
} else {
// refresh token 也过期,跳转登录
redirectToLogin()
}
}
return res
} catch (error) {
console.error(error)
}
}
# 滑动过期机制
- 每次请求都刷新 token 过期时间
- 类似于会话超时机制
- 优点:实现简单,用户体验好
- 缺点:安全性相对较低
# 无感刷新机制
在 token 即将过期时自动刷新 可以通过定时器或请求拦截器实现 优点:用户无感知,体验好 缺点:需要处理并发请求的问题
# 最佳实践
- 根据业务安全需求选择合适的方案
- access token 过期时间不宜过长(如 2 小时)
- refresh token 过期时间可以较长(如 7 天)
- 重要操作仍需要二次验证
- 考虑 token 注销机制
# 什么是 SSO 单点登录,描述它的工作过程
SSO (Single Sign On) 单点登录是一种身份验证机制,允许用户使用一组凭证访问多个相关但独立的系统。
# 基本概念
- 一次登录,全局通用
- 多个子系统共享用户会话
- 统一的认证中心
- 提高用户体验和安全性
# 工作流程
# 用户首次访问系统
- 用户访问系统 A
- 系统 A 检查无登录状态
- 重定向到 SSO 认证中心
- 带上系统 A 的地址作为参数
# SSO 认证中心处理
- 检查用户是否已登录 SSO
- 未登录则显示登录页面
- 用户输入账号密码
- 认证中心验证身份
# 回到系统 A
- SSO 生成票据(ticket)
- 重定向回系统 A
- 带上票据参数
- 系统 A 验证票据
- 创建本地会话
# 访问系统 B
- 用户访问系统 B
- 系统 B 检查无登录状态
- 重定向到 SSO 认证中心
- SSO 发现用户已登录
- 直接生成票据返回
- 系统 B 验证票据
- 创建本地会话
# 实现方式
- 基于 Cookie
- 基于 Token
- 基于 SAML
- 基于 OAuth
- 基于 CAS
# 优点
- 提升用户体验
- 减少密码管理
- 统一认证流程
- 提高安全性
# 缺点
- 认证中心单点故障
- 配置相对复杂
- 需要额外的安全考虑
# 什么是跨域?如何实现跨域通讯
跨域是指浏览器的同源策略限制,当前域名的 JavaScript 代码试图访问其他域名下的资源时会受到限制。
同源的定义:
- 协议相同(http/https)
- 域名相同
- 端口相同
# 跨域解决方案
# CORS(跨域资源共享)
- 服务器设置 Access-Control-Allow-Origin 等响应头
- 可以配置允许的请求方法、请求头、是否允许携带认证信息等
- 最常用的跨域解决方案
# JSONP
- 利用
<script>标签不受同源策略限制的特点,实现跨域请求 - 只支持 GET 请求
- 需要服务器配合返回 JavaScript 代码
# Proxy代理服务器
- 开发环境:webpack-dev-server、vite 等的 proxy 配置
- 生产环境:Nginx 反向代理
# WebSocket
- 建立在 TCP 之上的协议
- 天然支持跨域
- 适合需要实时通信的场景
# postMessage
- HTML5 标准中的 API
- 用于不同窗口间的跨域通信
- 可以在父子页面(iframe)或者多窗口间通信
最佳实践:
- 优先使用 CORS,配置得当的情况下最安全
- 需要兼容旧浏览器时可以考虑 JSONP
- 开发环境优先使用代理服务器
- 特殊场景(如页面通信)可以考虑 postMessage
- 需要实时通信时使用 WebSocket
# HTTP 请求跨域时为何要发送 options 请求
OPTIONS 请求是 CORS 预检请求(Preflight Request),用于检查实际请求是否可以安全地发送。
触发条件:
- 使用非简单请求方法:除 GET、POST、HEAD 之外的方法
- 使用非简单请求头:除 Accept、Accept-Language、Content-Language、Content-Type 之外的请求头
- Content-Type 不是以下之一:
- application/x-www-form-urlencoded
- multipart/form-data
- text/plain
# 工作流程
浏览器发送 OPTIONS 预检请求,包含:
- Origin:请求来源
- Access-Control-Request-Method:实际请求使用的方法
- Access-Control-Request-Headers:实际请求使用的请求头
服务器响应预检请求,返回:
- Access-Control-Allow-Origin:允许的源
- Access-Control-Allow-Methods:允许的方法
- Access-Control-Allow-Headers:允许的请求头
- Access-Control-Max-Age:预检请求的缓存时间
如果预检通过,浏览器才会发送实际请求
优化建议:
- 尽可能使用简单请求,避免触发预检
- 合理设置 Access-Control-Max-Age 缓存预检结果
- 服务端正确配置 CORS 响应头
# options 请求会携带 cookie 吗
OPTIONS 请求通常不会携带 Cookie。它是一个预检请求,用于检查实际请求是否可以安全地发送。浏览器在发送 OPTIONS 请求时,不会自动附带 Cookie 和 Authorization 等认证信息,除非明确设置了 credentials 选项。
如果需要在 OPTIONS 请求中携带 Cookie,可以在请求中设置 credentials: 'include',但通常不推荐这样做,因为 OPTIONS 请求的目的就是检查跨域请求的安全性,而不是进行身份验证。
# 简述浏览器的缓存策略
浏览器缓存策略主要分为两种:强缓存和协商缓存。
# 强缓存
- 不需要向服务器发送请求,直接使用本地缓存
- 通过 HTTP 响应头控制:
- Cache-Control:
- max-age:缓存有效时间(秒)
- no-cache:需要和服务器协商验证
- no-store:不使用任何缓存
- private:仅浏览器可缓存
- public:中间代理/CDN 等也可缓存
- Expires:过期时间点(已被 Cache-Control 取代)
- Cache-Control:
# 协商缓存
- 需要向服务器发送请求验证资源是否有效
- 如果有效返回 304,使用本地缓存
- 通过以下响应头实现:
- Last-Modified/If-Modified-Since:基于文件修改时间
- ETag/If-None-Match:基于文件内容哈希值
# 缓存位置(优先级从高到低)
- Service Worker
- Memory Cache(内存缓存)
- Disk Cache(硬盘缓存)
- Push Cache(HTTP/2)
# 缓存优先级
Service Worker -> Memory Cache -> Disk Cache -> Push Cache
# 缓存策略
- 强缓存优先于协商缓存
- 协商缓存由服务器决定是否使用缓存
- 协商缓存失效,返回 200,重新返回资源和缓存标识,再存入浏览器缓存中
- 协商缓存生效,返回 304,继续使用缓存
# 最佳实践
- HTML:使用协商缓存
- CSS、JS、图片:使用强缓存,文件名带 hash
- API 请求:根据业务需求设置合适的缓存策略
# 什么是图片防盗链,如何实现
图片防盗链是指服务器通过 HTTP 协议中的 Referer 字段来判断请求是否来自合法站点,从而防止其他网站直接引用本站图片资源。
实现方式:
服务器端实现
- 检查 HTTP Referer 字段
- 判断请求来源是否在白名单中
- 对非法请求返回 403 或替代图片
location ~ .*\.(gif|jpg|jpeg|png|bmp)$ {
valid_referers none blocked server_names *.example.com;
if ($invalid_referer) {
return 403;
# 或者返回替代图片
# rewrite ^/ /path/to/default.jpg break;
}
}
# 其他防盗链方案
- 给图片添加水印
- 使用 Token 验证
- 使用 CDN 提供的防盗链功能
- 对图片进行加密处理
# 注意事项
- Referer 可以被伪造,不能作为唯一判断依据
- 移动端 APP 可能不发送 Referer
- 部分浏览器可能禁用 Referer
- 需要考虑用户体验和 SEO 影响